
//1,2,3 일차 강의 요약 정리 노트본
SQL
실습 2
데이터 분석
select * from tableName limit 5;
select * from shareholder limit 5;
와일드 카드
"%"를 사용하여 유사 검색어 찾기
시작하는 검색
select * from tablename where column like "%keyword"
끝나는 검색
select * from tablename where column like "keyword%"
포함하는 검색
select * from tablename where column like "%keyword%"
데이터 정렬하기
order by column_name;
order by column_name desc;
데이터 삽입하기
Insert into tableName(column_name1, column_name2)
values ("value1", "value2");
데이터 수정하기
update tableName
set columnName = "newValue"
where columnName = "oldValue"
실습 3
데이터 숫자 세어보기
count(*)
count(column_Name)
일부 데이터만 출력
limit by number;
데이터 합 구하기
sum(column_name)
데이터 평균 구하기
avg(column_name)
데이터 최대 /최소 값 구하기
max(column_name)
min(column_name)
실습 4
집합 연산자 : UNION (합집합, 중복제거)
(SELECT store_name
FROM chicken_store
WHERE available = 'Y') UNION
(SELECT store_name
FROM pizza_store
WHERE available = 'Y') order by store_name;
집합 연산자 : UNION ALL (합집합, 중복제거하지 않음)
SELECT lecture_name FROM lecture_basic
UNION ALL
SELECT lecture_name FROM lecture_special
order by lecture_name ;
집합 연산자 : INTERSECT (교집합)
(SELECT name, email FROM student)
INTERSECT
(SELECT name, email FROM lecture_special);
집합연산자 : EXCEPT (집합 A - 교집합)
(SELECT student_number, student_name FROM lecture_special)
EXCEPT
(SELECT student_number, student_name FROM lecture_basic) order by student_number;
집합연산자 : 카티션 프로덕트 : CROSS JOIN
실습 5
단일행 서브쿼리
select * from tableName
where column_name > (
select column_name
from tableName
where column_name = value
)
다중행 서브쿼리
select * from tableName
where column IN (
select column_name
from tableName
where column_name = value
)
select * from tableName
where column ALL (
select column_name
from tableName
where column_name = value
)
select * from tableName
where column ANY (
select column_name
from tableName
where column_name = value
)
SELECT product_id, product_name
FROM PRODUCT
WHERE stock >= 1
AND (product_id, product_name) IN (
SELECT product_id, product_name
FROM ELICE_MART
WHERE stock = 0
) order by product_id;
실습 6
뷰
CREATE VIEW EMPLOYEE_DEV AS
SELECT employee_id, salary
FROM EMPLOYEE
WHERE department_name = '개발';
연습장
Left join : 왼쪽 데이블이 데이터 기준으로 검색되도록 수행
SELECT *
FROM salaries
LEFT JOIN employees ON salaries.emp_no = employees.emp_no;
Inner join : 양쪽 테이블 모두에 존재하는 데이터만 추출
SELECT *
FROM salaries
INNER JOIN employees ON salaries.emp_no = employees.emp_no;
ColumnName In 다중행 서브쿼리 :
SELECT book_id, book_name, book_writer, price
FROM BOOK
WHERE book_id IN (
SELECT book_id
FROM BOOK_STOCK
WHERE stock >= 1
);
구문 복습 :
DISTINCT column _name :
SELECT DISTINCT department
FROM employees;
column_name BETWEEN A and B :
salary BETWEEN 50000 AND 80000;
column_name IN 다중데이터 :
IN ('HR', 'Finance', 'Marketing');
DML
LIKE
ORDER BY
INSERT INTO , VALUES
UPDATE
DELETE
HAVING : WHERE과 유사하나 Group by 된 결과에 대해서 추가 조건절로 사용 가능.
GROUP BY department HAVING AVG(salary) >= 60000;
INNER JOIN / ON : On에서 조건을 넣어주어야 결합된 테이블이 생성 가능함.
JOIN departments d ON e.department_id = d.department_id;
LEFT JOIN / RIGHT JOIN
RANK / DENSE_RANK / ROW_NUMBER
SELECT employee_id, employee_name, department_id,
RANK() OVER (PARTITION BY department_id ORDER BY employee_id) AS ranking
FROM employees;
select todo, target_date,
RANK() over (partition by todo order by target_date) as ranking
from park_todo_db;
SELECT employee_id, employee_name, department_id,
DENSE_RANK() OVER (ORDER BY department_id) AS dense_rank
FROM employees;
SELECT employee_id, employee_name, department_id,
ROW_NUMBER() OVER (ORDER BY department_id) AS row_num
FROM employees;
FRIST_VALUE / LAST_VALUE / LAG / LEAD
SELECT department, employee_name, salary,
FIRST_VALUE(employee_name) OVER (PARTITION BY department ORDER BY salary DESC) AS highest_paid_employee
FROM employees;
//시험 예상문제 (강사님 제공)
SQL실습2 퀴즈2 : 데이터 정렬 (내림차순)
Order by x DESC
SQL실습3 퀴즈2 : 테이블 안에 있는 정보 5개만 조회
select * from table_name limit 5;
SQL실습3 퀴즈3 : 총점 / 평균 값 산정
select sum(math) from table_name;
Inner join 조인조건문 서술 :
select *
from salaries
inner join employees on salaries.emp_no = employees.emp_no;
having 빈칸채우기 :
group by department having avg(salary) >= 6000
any :
where column any ('1', '2', '3')
like 연산자 사용 :
select * from table_name where column like "%keyword%"
sql명령문 서술순서 :
(select from where group by having order by)
//Rank() 부분 관련 결과 보충 설명 :
– Rank() over (partiton by column_name order by column_name)
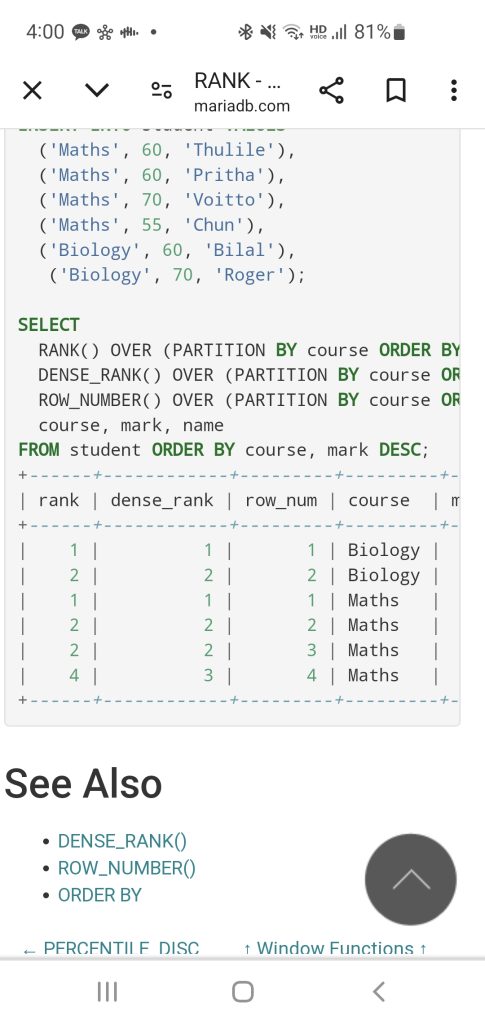
//SQL 실습 답안 : 나스카 이슈로 문서가 보이지 않는 것으로 보임.
SQL 실습 답안 (1)